
If you’ve seen my latest blog posts on the company blog about how to build an IOT analytics platform with the SMACK stack, you’ve seen how I used my second favorite Apache product Apache Cassandra to store spatial data.
This Blog is about my favorite Apache product Apache Karaf, and how easy it actually is to build a Monitoring solution for Apache Cassandra as being part of the SMACK stack.
For all people not nowing about the SMACK stack, it’s actually a combination of great Apache Produkts:
- Apache Spark
- Apache Mesos
- Apache Cassandra
- Apache Kafka
- and Akka as glue for those
More on how to run this IOT analytics platform on DC/OS can be found in my second blog about this topic.
Apache Karaf Decanter …
Apache Karaf Decanter is a sub project of Apache Karaf, it gives extra logging functionalities on top of Apache Karaf. In short it’s Elasticsearch and Kibana plus some extra collecting bundles running inside Apache Karaf. Those extra collecting bundles are the keypoint for Apache Karaf Decanter. With some simple configurations it’s possible to collect data from any JMX resource, like the local data available from Karaf or any other JMX endpoint.
An in detail description of Apache Karaf Decanter and it’s possibilities can be found at this blog.
… monitoring …
To build your own monitoring solution with Apache Karaf Decanter is quite easy, especially if it’s just collecting data from an JMX endpoint. On a vanilla Apache Karaf just install everything which is required to monitor any application. In our case it’s simple:
- feature:install elasticsearch
- feature:install kibana
- feature:install decanter-appender-elasticsearch
- feature:install decanter-collector-jmx
With those features installed, you’ll run an Apache Karaf with embedded elasticsearch, Kibana and a jmx collector which retrieves all JMX data from the local Karaf server.
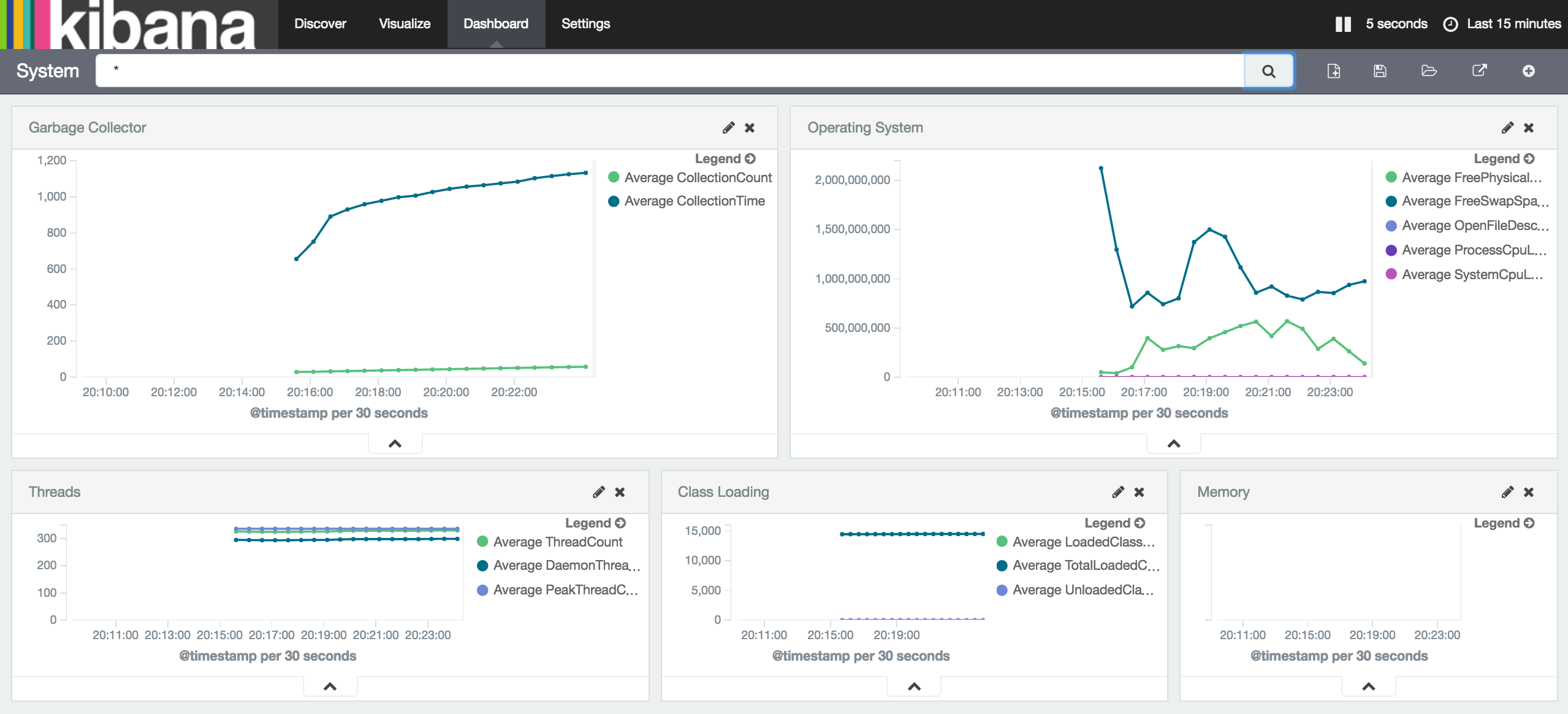
… your Apache Cassandra servers …
To actually monitor your Apache Cassandra server, it only takes a JMX collector to do so. In our simple sample right now, we expect this Apache Cassandra server to be running on the same instance the Apache Karaf is running on. This does have a reason, as Apache Cassandra starts with a local JMX port enabled.
To collect data from this locally running Apache Cassandra it’s just needed to add the following code as configuration file in the etc – folder of the Apache Karaf server as
org.apache.karaf.decanter.collector.jmx-cassandra.cfg
# # Decanter Apache Cassandra JMX collector configuration # # Name/type of the JMX collection type=jmx-cassandra # URL of the JMX MBeanServer. # local keyword means the local platform MBeanServer or you can specify to full JMX URL # like service:jmx:rmi:///jndi/rmi://hostname:port/karaf-instance url=service:jmx:rmi:///jndi/rmi://localhost:7199/jmxrmi # Object name filter to use. Instead of harvesting all MBeans, you can select only # some MBeans matching the object name filter object.name=org.apache.cassandra.metrics:type=*,scope=*,name=*
With such a configuration you’ll have a perfectly running local Apache Karaf Decanter setup to Monitor
a) your local Apache Karaf
b) a Apache Cassandra.
… in a SMACK environment
While the previous setup is perfectly fine for a standalone monitoring solution or as local Kibana dashboard development environment, it doesn’t suite a monitoring solution for an environment which contains various Apache Cassandra instances.
The SMACK stack of the IOT analytics platform consists of 3 Cassandra Instances, so it is crucial to monitor all three instances. One solution would be to configure those instances to not only open a local JMX port, but to also open a remote JMX connection. The drawback of this solution, it’s not possible as the mesos framework for Apache Cassandra doesn’t have any options to configure this. So it’s crucial to have something capable of collecting JMX data from the local JMX server and transfer this data to a running elastic server.
Apache Karaf Decanter to the rescue! At this point the full potential of OSGi managed services inside Apache Karaf can be used.
A vanilla Apache Karaf instance with the following two Decanter features is needed:
- decanter-collector-jmx-core
- decanter-appender-elasticsearch-rest-core
But without proper configuration no services will be available and therefore no monitoring.
Take the configuration listed above for collecting the data from the local JMX cassandra instance and add another configuration for the elasticsearch rest appender.
org.apache.karaf.decanter.appender.elasticsearch.rest.cfg
######################################################### # Decanter Elasticsearch HTTP REST Appender Configuration ######################################################### # HTTP address of the elasticsearch node # NB: the appender uses discovery via elasticsearch nodes API address=http://elasticsearch-executor.elasticsearch.mesos:1025 # Basic username and password authentication # username=user # password=password
With those configurations we’re set. But how to have those features and configurations available as deployment on our mesos cluster?
The easiest way to achieve this is to build a custom Apache Karaf Decanter distribution with those features pre-installed and those configurations enabled.
An example of how to build such a custom distribution can be found at this corresponding project: https://github.com/ANierbeck/Karaf-Decanter-Runtime
To deploy a custom distribution on Mesos you’ll need to deploy it as a marathon application.
{
"id": "/decanter",
"cmd": "export PATH=\$(ls -d \$MESOS_SANDBOX/jdk1*/bin):\$PATH && export JAVA_HOME=\$(ls -d \$MESOS_SANDBOX/jdk1*) && ./Decanter-Runtime-0.1.0-SNAPSHOT/bin/karaf\n",
"cpus": 0.2,
"mem": 512,
"disk": 0,
"instances": 3,
"executor": null,
"fetch": [
{
"uri": "<URL_TO_JDK>/jdk-8u102-linux-x64.tar.gz"
},
{
"uri": "https://oss.sonatype.org/content/repositories/snapshots/de/nierbeck/karaf/decanter/Decanter-Runtime/0.1.0-SNAPSHOT/Decanter-Runtime-0.1.0-20161014.113802-11.tar.gz"
}
],
"constraints": [
[
"hostname",
"UNIQUE",
""
],
[
"hostname",
"LIKE",
"<CASSANDRA_CONNCET_LIKE>"
]
],
"acceptedResourceRoles": null,
"user": null,
"container": null,
"labels": null,
"healthChecks": [
{
"protocol": "COMMAND",
"command": {
"value": "pgrep java && exit 0 || exit 1"
},
"gracePeriodSeconds": 300,
"intervalSeconds": 60,
"timeoutSeconds": 20,
"maxConsecutiveFailures": 3
}
],
"env": null,
"portDefinitions": [
{
"protocol": "tcp",
"port": 0
}
]
}
Make sure to replace the placeholder with a real URI to a jdk which is available for your cluster to download. Another placeholder to replace , is needed to specify the instances on which cassandra resides on.
Schreibe einen Kommentar